ChimStat
Présentation du logiciel
L'outil Phytostat est un logiciel de traitement de données permettant la classification,
l'entraînement de modèles puis la prédiction de classe géographiques. Il est basé sur l'utilisation des modules scikit-learn, numpy, pandas et l'interface graphique est basé sur shiny.
L'outil se décompose en différents onglets correspondant à des tâches spécifiques :
- Onglet Training des modèles : Permet l'entraînement des modèles à partir des données d'entrées.
- Onglet Prédiction sur nouvelles données : Permet la prédiction de classe sur de nouveaux échantillons.
- Onglet Clustering geographiques : Permet de détecter le nombre optimal de région différentes dans un jeu de données à partir des coordonnées GPS.
Quelles sont les données d'entrées ?
Les données d'entrées doivent se présenter sous la forme d'un fichier csv.
L'architecture globale des données d'entrées est la suivante :
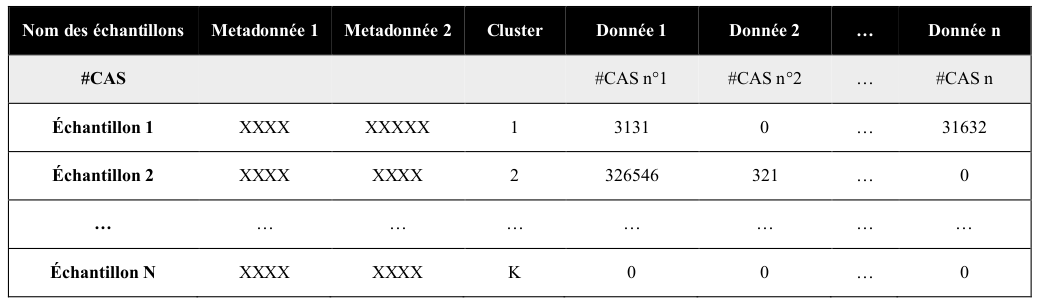
La ligne #CAS peut être vide mais doit malgré tout exister.
Ce format est valable pour la création des modèles mais aussi pour la prédiction
Quelles sont les sorties ?
Les sorties sont des fichiers csv pour les métriques, les prédictions et les données transformées; des fichiers sav pour les modèles de réduction de données et de classification; des graphiques au format html et png. Ils sont automatiquement enregistrés dans le dossier de travail, dans des dossiers spécifiques.
Liste des onglets
- La barre latérale
- Données complètes
- Visualisation des données
- Contribution
- Screeplot
- Matrice de confusion
- Paramètres du modèles
- Contributiom des molécules
- Intervalles de confiance
Informations générales
Cet onglet est organisé en sous onglet permettant la visualisation des différentes étapes, données ou
sorties. L'ensemble des modèles créés est issu du module sklearn dont la documentation est
disponible ici :
https://scikit-learn.org/stable/modules/classes.html. Les liens clicables de la page dirige vers la documentation de la fonction sklearn correspondante.
Quelque soit les paramètres choisis le pipeline de traitement de données est toujours le même.
- Chargement des données.
- Prétraitement des données : Séparation en un jeu d'entraînement et un jeu de test.
- Reduction de dimensionnalité : Elle se fit sur les données d'entraînement avant d'être appliquée aux deux jeux
- Entraînement des modèles : Le classifier est entraîné sur le jeu d'entraînement. Cette étape est soumise à une procédure de validation croisée qui permet de limiter le surajustement des modèles.
- Prédiction : La prédiction est faite sur le jeu de test.
- Evaluation : L'evaluation des modèles est faite sur les prédictions issues du jeu de test.
- Sauvegarde des modèles : Les modèles sont entraînés sur le jeu complet et sont sauvegardés.
La barre latérale
Les différentes entrées permettent de paramétrer l'entraînement des modèles que ce soit sur la réduction de dimensionnalité ou les modèles de classifications. Elle permet aussi de stipuler le format des données (colonnes des cibles à prédire, colonnes des données à utiliser.)
- Sélection du dossier de travail : Sélection le dossier dans lequel sera sauvegardé automatiquement tout ce que produit l'application. Par défaut le dossier est là où se trouve le script app.py
- Sélection du/des fichiers
- Colonne des données : Numéro de colonne à partir de laquelle toutes les colonnes suivantes (elle y compris) correspondent aux variables explicatives. Les colonnes précédentes ne seront pas prises en compte dans les modèles
- Colonne de cluster : Designe le numéro de colonne dans laquelle se trouve la cible à prédire (cluster, catégories etc)
- Fusion de données : Permet de fusionner plusieurs csv partageant les mêmes identifiants d'échantillons (fusion de fichier issu de différentes méthodes).
- Nombre de composantes : Dans l'étape de réduction de dimensionnalité, le nombre de dimension utilisé
- Nombre de cross validation : Nombre de validation croisée à effectuer. Chiffre compris entre 2 et +Inf.
- Taille du test : Pourcentage du fichier utilisé pour calculer les métriques de précision des modèles. Compris entre 1 et 100, mais si trop grand risque élevé de bugs.
- Données : Méthodes de réduction de dimensionnalité à utiliser. Toutes les combinaisons sont possibles. Au moins une à sélectionner (Brutes signifie pas de transformation des données)
- Classifier : Algorithme de classification à utiliser. Les noms font référence aux noms
utiliser
dans le module
sklearn - KNN : K-Nearest Neighbors. Méthode d'attribution par proximité avec les points connus
- LDA : Linear Discriminant Analysis. Méthode linéaire de discrimination des données qui définit des plans de séparations des données
- QDA : Quadratic Discriminant Analysis. Similaire à la LDA mais avec des relations quadratiques
- PLS-DA : Partial Least Squares Discriminant Analysis. Similaire à la LDA
- MLP : Multilayer Perceptron. Algorithme simple de réseaux de neurones
- Decision Tree : Decision Tree
- Random Forest (RDF)
- SVM : SVM Radial ou Polynomial
- Naive Bayes Gaussian : Classification probabiliste utilisant le théorème de Bayes
- Ridge : Ridge. Régression linéaire permettant une classification a posteriori
- Multinominal Logistic Regression : Logistic Regression
- Bouton "Générer les modèles"
Donnés complètes
Cette onglet permet de visualiser le fichier utilisé pour l'entraînement des modèles. Il réagit au changement de lié à la fusion de données.
De plus, cette onglet permet de visualiser les variables explicatives pour un échantillon sélectionné (clic sur la ligne).
Sélection de variables
Après entraînement des modèles, cette onglet permet de voir la variance associée à chaque variable dans la réduction de dimensionnalité et de sélectionner uniquement les variables d'intérêt. Il est alors possible de recommencer un entraînement uniquement avec ces variables.
Visualisation des données
Les onglets Plot 3D et Plot 2D permettent de visualiser les données dans un espace à 2 ou 3 dimensions (si les données le permettent). De plus, à chaque graphique généré, il est automatiquement enregistré dans le dossier graphique se trouvant dans le dossier de travail sélectionné au début. Il est possible de choisir ici les dimensions selon lequel le graphique est fait .
Contribution
Cet onglet permet, lorsqu'une méthode de réduction de dimensionnalité est appliquée, de visualiser la contribution de chaque variable à chaque dimension.
Scree Plot
Le screeplot est un outil qui permet de déterminer visuellement qu'elle peut être le meilleur nombre de dimension dans l'étape de réduction de dimensionnalité
Matrice de confusion
Dans cet onglet, différentes métriques de quantification des modèles sont affichées : une matrice de confusion, une matrice avec les scores de validation croisées (précision, sensibilité, F1-score) et un tableau des résultats en termes de faux/vrai positifs/négatifs.
Paramètres des modèles
Durant la phase d'optimisation, certains hyper-paramètres sont optimisés et affichés ici.
Contribution des molécules
Si la ligne 2 du fichier n'est pas vide (numéro CAS), ici est affiché un tableau avec la contribution et la formule de la molécule.
Intervalles de confiance
Cet onglet affiche l'histogramme des probabilités obtenu dans chaque variable, dans chaque catégorie de prédiction (faux/vrai positifs/négatifs).
Visualisation
La visualisation des données permet une meilleure compréhension de la structure des
données. Différentes visualisations sont proposés et permettent
une première interprétation des données.
Il est basé sur l'utilisation des modules
scikit-learn, numpy, pandas et plotly et l'interface graphique est basé
sur shiny.
Chaque onglet permet de paramétrer une visualisation particulière.
Quel type de visualisation
Le premier onglet permet de visualiser les données d'entrée. Il permet de voir la distribution des donnée. Il permet aussi de visuellement s'assurer du bon numéro de colonne pour les cluster et les données. Ces inputs sont nécessaires avant la visualisation graphique
Le deuxième onglet permet de visualiser le spectre de chaque échantillon sélectionnés sur le premier onglet en cliquant sur la ligne. Cette visualisation est particulièrement adaptée pour les applications en chimie analytique.
Le troisème onglet permet de calculer des indices de distributions. Il permet d'effectuer les taches de statistiques descriptives pour chaque variable.
Le quatrième onglet permet de représenter sous forme de barplot, la distribution des
différentes classes présentes dans la colonne cluster. Cet onglet est
important pour le diagnostic préalable à la classification, équilibrage du jeu d'entraînement.
Le cinquième onglet permet de représenter la distribution des variables sous forme de boxplot. Il est possible de choisir les variables représentées en tapant leur numéro dans la zone de texte.
Le dernier onglet permet de représenter les données sous formes de heatmap binaires ou quantitatifs. La version quantitative est clusterisé par ligne et colonne afin de regrouper les données similaires ensemble.
Comment les interpréter
La plupart des onglets permettent simplement une visualisation et une description des données sans forcément d'intérpretation. Cependant, le graphique de fréquence des classes est particulièrement intéressant dans le cadre de la classification car il permet de vérifier que le jeu de données n'est pas déséquilibré vers une classe particulière ce qui pourrait biaiser l'entraînement.
Prédiction sur nouvelles données
Cet onglet permet de prédire la classe de nouveaux échantillons. Pour cela des modèles doivent avoir été construit à l'étape précédente. Divers onglets permettent de visualiser les prédictions soit sous la forme d'un tableau soit sous la forme d'un graphique. Enfin il est possible d'utiliser de multiples modèles qui sont moyennés pour prendre en compte les erreurs et biais associés à chaque modèle. L'ensemble des prédictions sont enregistré dans un dossier prediction du dossier de travail.
La barre latérale
La barre latérale permet comme à l'étape précédente de sélectionner les fichiers et les modèles à utiliser. Pour la prédiction, le dossier de travail doit contenir les dossier methods et classifier (automatiquement créés à l'étape précédente) contenant les modèles. Sans ces modèles, il est impossible de faire de la prédiction.
- Colonne avec ID : Colonne utilisé pour identifier les échantillons à prédire.
- Colonne des données : Colonne à partir de laquelle toutes les autres colonnes sont des variables.
- Données : Méthode pour la réduction de dimensionnalité
- Classifier : Classifier à utiliser
- Niveau de fusion de données : Fusion de données à utiliser
- Composantes : Composante à utiliser pour la représentation graphique
- Sélection de modèles : Sélection des modèles (.sav) à utiliser pour l'utilisation de la moyenne sur l'ensemble des modèles sélectionnés
Création de modèle quantitatif
Modele quantitatif
Masse spectrométrie
Présentation de l'outil
Cet onglet permet de traiter les fichiers issus de l'analyse de spectrométrie.
Une première étape permet de convertir les fichiers raw en ficher mzxML. Plusieurs fichiers peuvent être convertis en même temps.
La seconde permet, à partir des fichiers convertis, d'étudier les spectres obtenus et d'en extraire automatiquement les spectres. Il est possible de sélectionner le degré de lissage de l'algorithme, le nombre de pic à extraire ainsi que la précision autour du pic à extraire.
Le spectre ainsi que les fenêtres de chaque pic (début en vert et fin en rouge) sont affichés.
Enfin, le tableau actualisé avec les pics s'affiche en dessous en montrant les intensités moyennes, les temsp de rétentions de début et de fin de pic. Ce tableau ainsi que l'ensemble des intensités pour chaque rapport m/z sont enregistrés dans le dossier output.
Clustering
Fichier d'entrée
L'onglet Clustering géographique permet à partir d'un fichier de coordonnées GPS de déterminer le nombre optimal de clusters dans le jeu de données.
Le fichier d'entrée se présente sous la forme d'un tableau excel (xlsx) où l'un des colonnes représente les coordonnées géographiques dans le format "lat,lon". Elle sera spécifié dans la case "Colonne(s) de coordonnées".
Il est aussi possible que les données géographiques soit sous forme de 2 colonnes. Il faut alors indiquer, dans cette même case, la colonne latitude puis la colonne longitude, séparées par un point virgule.
Algorithme de clustering
L'Algorithme utilisé est un K-Means. Le nombre de groupe est défini dans la case "Nombre de groupe".
Cela fonctionne par processus itératif. K centroides sont placés aléatoirement dans l'espace des points de données. Chaque point est alors attribué au centroide le plus proche. Les centroides sont alors recalculés comme le centre des points qui lui ont été attribués. À chaque étape, des mesures de distances inter et intra groupes sont faites. Elles permettent en étudiant leur évolution de quantifier la convergence du processus et de décider d'un moment d'arrêt.
Sorties
Le tableau actualisé avec les cluster s'enregistre automatiquement dans le dossier output. De plus la carte avec les points attribués à leur cluster est aussi enregistrée automatiquement dans le dossier graphique.
Enfin, le graphique permettant de choisir le meilleur nombre de groupe est disponible aussi dans le dossier graphique.